| Home |
| Computing |
| Cognition |
| Language Learning |
| Book |
SIMPLICITY AND POWER
Some Unifying Ideas in Computing
Gerry Wolff
School of Electronic Engineering Science, University of Wales (Bangor),
Dean Street, Bangor, Gwynedd, LL57 1UT, UK. +44 248 351151 ext 2691
Issue: 1.1
20 September 1988
This article is to appear in the Computer Journal
- DOCUMENT CONTROL
- 1.1 Changes History
- 1.2 Changes forecast
- ABSTRACT
- INTRODUCTION
- SIMPLICITY AND POWER IN GRAMMARS AND COMPUTING SYSTEMS
- 4.1 Redundancy, Structure and Inductive Reasoning
- 4.2 Grammatical Inference
- 4.3 Grammars and Other Systems
- 4.4 An Analogy
- 4.5 Constraint and Freedom, Power and Simplicity, AND Relations and OR Relations
- 4.6 Efficiency and Redundancy Extraction
- 4.7 Pattern Matching and the Hill-Climbing Search for Efficient Structures
- 4.8 De-referencing as Pattern Matching and Unification
- 4.9 Modelling the World
- 4.10 Useful and Useless Redundancies
- 4.11 Summary
- ORGANIZING PRINCIPLES
- 5.1 AND Relations
- 5.2 OR Relations
- THE SP LANGUAGE
- APPLICATIONS
- CONCLUSION
- ACKNOWLEDGEMENTS
- REFERENCES
- APPENDIX: THE CALCULATION OF SIZE, POWER AND EFFICIENCY OF GRAMMARS
- FIGURE CAPTIONS
1. DOCUMENT CONTROL
Issue 0.1 to 0.9 - earlier drafts each with limited circulation.
Issue 1.0 (26 April 1988) - issue 0.9, has been carefully revised in the light of comments from anonymous referees and from colleagues.
Issue 1.1 (20 September 1988) - the document has been reformatted using Framemaker, and small changes have been made to the text in the light of comments from an anonymous referee .
1.2 Changes forecast
None. This version of the document has been accepted for publication in the Computer Journal.
2. ABSTRACT
The article develops the conjecture that the organization and use of all kinds of formal system, knowledge structure or computing system may usefully be seen in terms of the management of redundancy in information.
Every formal system, knowledge structure or computing system has two key dimensions - simplicity (complexity or size) and expressive or descriptive power - and there is a trade-off between them. The balance between simplicity and power corresponds to a balance between OR relations and AND relations in the system.
The efficiency of the system (the ratio of power to size) depends on the extraction of redundancy from the system. Key mechanisms for the extraction of redundancy are pattern matching and search (by hill climbing or equivalent mechanism) for the greatest possible unification of patterns.
These principles are the basis of a proposed new language and associated computing machine, called SP, which combines simplicity with high expressive power. SP is a Prolog-like pattern- matching system well suited to high levels of parallelism in processing.
In SP, the boundary between 'knowledge engineering' and other kinds of information engineering breaks down. In SP there is the potential for full integration of artificial intelligence, software engineering and other aspects of computing - with Shannon-Weaver information theory as a unifying framework. SP also offers a bridge between 'connectionist' and 'symbolic' views of computing.
SP, and the principles on which it is based, have potential applications in several areas of computing including:
- Logic and logical inference.
- Formal specification of computing systems.
- Inductive learning.
- Pattern recognition.
- Object-oriented design and conceptual modelling: class-inclusion relations, part-whole relations, inheritance of attributes - and the integration of these constructs. SP supports intensional and extensional descriptions of classes and the creation of entity-relationship models.
- The representation of knowledge in expert systems and databases; information retrieval and content addressable memory.
- Probabilistic inference and reasoning with uncertain and incomplete knowledge.
- The representation of plans and the automatic generation of plans.
- Specification of the organization of natural languages including 'context sensitive' features.
- Software re-use and configuration management.
- The integration of diverse kinds of knowledge which is required in many applications including integrated project support environments; facilitation of translations between computer languages and between one form of knowledge and another.
3. INTRODUCTION
There is a Babel of languages, formalisms and representational systems in computing and a diversity of concepts. Some of this variety is useful but much of it is not. There is a need to rationalise and integrate computing ideas and to achieve a corresponding simplification of the subject.
Simplicity in itself is not enough. We could, for example, propose the very simple theory that all (digital) computing is about storing and manipulating bits. This theory is too simple to be illuminating. We need a view of computing which is simple but which also has explanatory and expressive power.
This article proposes some principles which can lay some claim to providing that desirable marriage of simplicity and power. The principles are embodied in a proposed new computing language and associated computing machine called 'SP'. The name SP is mnemonic for 'Simplicity' and 'Power'; it is also mnemonic for 'Syntagmatic' and 'Paradigmatic', two concepts from taxonomic linguistics which figure prominently in the system.
SP is a Prolog-like pattern-matching system well suited to high levels of parallelism in processing. The justification for creating yet another language is the expectation that it will lead to an overall simplification of the field.
In SP, the boundary between 'knowledge engineering' and other kinds of information engineering breaks down. In SP there is potential for the full integration of artificial intelligence, software engineering and other aspects of computing - with Shannon-Weaver information theory as a unifying framework. SP also offers a bridge between 'connectionist' and 'symbolic' views of computing.
The principles and the system have potential applications in several areas of computing including:
- Logic and logical inference.
- Formal specification of computing systems.
- Inductive learning.
- Pattern recognition.
- Principles of object-oriented design and conceptual modelling: class-inclusion relations, part-whole relations, inheritance of attributes - and the integration of these constructs. SP supports intensional and extensional descriptions of classes and the creation of entity- relationship models.
- The representation of knowledge in expert systems and databases; information retrieval and content addressable memory.
- Probabilistic inference and reasoning with uncertain and incomplete knowledge.
- The representation of plans and the automatic generation of plans.
- Specification of the organization of natural languages including 'context sensitive' features.
- Software re-use and configuration management.
- The integration of diverse kinds of knowledge which is required in many applications including integrated project support environments; facilitation of translations between computer languages and between one form of knowledge and another.
4. SIMPLICITY AND POWER IN GRAMMARS AND COMPUTING SYSTEMS
The ideas to be described derive most immediately from work on the inductive learning of grammars and from an analysis of cognitive development (see, for example, Wolff, 1982, 1987; an overview is presented in Wolff, 1988). I don't intend to discuss these fields in detail - merely to sketch the ideas which are relevant here.From this work on inductive learning has emerged the conjecture that knowledge representation and inductive learning may both usefully be seen in terms of the management of redundancy in information. The idea has now been generalized to the conjecture that: the organization and use of all kinds of formal system, knowledge structure or computing system may usefully be seen in terms of the management of redundancy in information.
Key ideas in the management of redundancy in a knowledge structure are:
- The detection of redundancy by pattern matching and
- The reduction of redundancy in the structure by searching for the greatest possible unification of patterns (using hill climbing or related process).
As I shall try to show, the extraction of redundancy by pattern matching and unification of patterns can provide a unified view of several concepts in computing. Since the concept of redundancy is part of Shannon-Weaver information theory, information theory is a foundation for the theory to be described.
The idea of searching for economical structures has figured in research on 'neural computing' (see, for example, Rumelhart & McClelland, 1986) and, indeed, in research on cluster analysis and numerical taxonomy. This article presents a view of computing which is not tied to any particular architecture (such as neural networks) and which is in several other respects different from work on neural computing or cluster analysis. In many ways it is complementary to these fields. In particular, it may be seen as a bridge between the purely connectionist and 'sub-symbolic' views of computing associated with research on simulated neural nets and the more traditional 'symbolic' views of computing.
4.1 Redundancy, Structure and Inductive Reasoning
Before we proceed to examine these ideas, there are some general points to be made about redundancy:- Redundancy means Repetition of Information. Although this is not always obvious,
redundancy in information (and thus all kinds of structure - see below) always means
repetition of information. Repetition of information always means redundancy.
- Redundancy and Structure. The concept of redundancy (in the Shannon-Weaver sense)
is closely related to the concept of structure. A body of information which has no
redundancy is entirely random; it is 'white noise' with a maximum of entropy; it has no
structure. The structure of a body of information may be equated with the patterns of
redundancy in it. Thus any discussion of the structure or organization of a body of
information may be mirrored by a corresponding discussion about the redundancy in the
information.
- Redundancy and Inductive Reasoning. Whatever the particular reasons for storing and
manipulating information (in computing systems, on paper, or in our heads) the underlying
reason is always to make predictions. The principle of inductive reasoning - that the past
is a guide to the future - is the basis of all kinds of natural or artificial cognition.
Inductive reasoning depends on repetition of information: patterns of information which have repeated in the past are assumed to repeat in the future. Given that repetition of information also means redundancy, we can see that inductive reasoning (and thus all kinds of natural and artificial cognition) depends on the existence of redundancy in the world.
A world without redundancy would not permit prediction. It would lack any structure; there would be no point in storing or manipulating information because that information would provide no means of anticipating the future.
These ideas have a bearing on the philosophical problem of finding a rational basis for inductive reasoning but it would take us too far afield to discuss this interesting question here.
In the following subsections I discuss the significance of redundancy in more detail using grammatical inference (inductive learning) as a way of introducing the main concepts.
4.2 Grammatical Inference
Grammatical inference is a process of discovering, inducing or constructing a grammar from a body of 'raw' data - typically a string of characters or a set of strings of characters. The grammar which is inferred from the string or strings may be seen as a means of succinctly describing those strings.There are always many grammars which are compatible with a given body of raw data, in the sense that they can 'generate' that body of data; some of these alternative grammars are, in some sense, 'better' than others. The inference problem is to find the 'best' grammar or, more realistically, to find one which is 'good enough'.
Two key measures of 'goodness' are: the compactness, size or simplicity of a grammar; and its usefulness, expressiveness or power for describing data. The words with emphasis have been chosen deliberately to show the parallel with the need for both simplicity and power in how we think about computing.
Consider Figure 1. The 'raw' data at the top of the figure may be represented by a number of alternative grammars. In the first, labelled "Primitive Grammar 1", we simply give a label '1' to the whole string of data. This primitive grammar is not at all compact: apart from the label, it is exactly the same size as the original data. But it is very 'powerful' in the sense that it may be used to represent the original data succinctly in other contexts by means of the symbol '1'.
The same raw data may also be represented by "Primitive Grammar 2" in which each type of letter is represented by a digit. If rules are selected repeatedly from this primitive grammar it can 'generate' the original data. This grammar is very simple and compact - but it is not at all powerful: a description of the original data using the grammar is as big as the original data (see Figure 1).
These two primitive grammars represent extremes of a trade-off between simplicity and power. Between the two extremes lies a whole range of grammars covering a whole range of combinations of simplicity and power. The problem of grammatical inference is to find grammars, like the two 'well-structured' grammars in Figure 1, in which that combination is at or near a maximum.
The first well-structured grammar in Figure 1 is just as expressive (powerful) as the first primitive grammar (because the original data may be represented with the single symbol '1') but it is more compact (simple) and thus represents an improvement over the first primitive grammar.
The second well-structured grammar in Figure 1 is as simple as the second primitive grammar but it is more powerful because the grammar may be used to encode the original data in a more economical form than with the second primitive grammar (as shown in Figure 1).
As a contrast to the two well-structured grammars, consider the two badly structured grammars in Figure 1. The first badly structured grammar is as powerful as the first well-structured grammar but it is less compact. We can say that it is relatively 'inefficient' compared with the first well- structured grammar because it has a relatively poor ratio of power to size.
The second badly structured grammar is as simple as the second well-structured grammar but it is less powerful. Again, its efficiency is low compared with the corresponding well-structured grammar. There are many possible inefficient grammars like this which should be rejected by the grammar induction process.
RAW DATA
A,B,C,D,P,Q,R,A,B,C,D,A,B,C,D,P,Q,R,A,B,C,D,P,Q,R,P,Q,R,A,B,C,D
PRIMITIVE GRAMMAR 1
1 --> A,B,C,D,P,Q,R,A,B,C,D,A,B,C,D,P,Q,R,A,B,C,D,P,Q,R,P,Q,R,A,B,C,D
Encoding of raw data: 1
PRIMITIVE GRAMMAR 2
1 --> A
2 --> B
3 --> C
4 --> D
5 --> P
6 --> Q
7 --> R
Encoding of raw data: 1,2,3,4,5,6,7,1,2,3,4,1,2,3,4,5,6,7,1,2,3,4,5,6,7,5,6,7,1,2,3,4
WELL STRUCTURED GRAMMAR 1
1 --> 2,3,2,2,3,2,3,3,2
2 --> A,B,C,D
3 --> P,Q,R
Encoding of raw data: 1
WELL STRUCTURED GRAMMAR 2
1 --> A,B,C,D
2 --> P,Q,R
Encoding of raw data: 1,2,1,1,2,1,2,2,1
BADLY STRUCTURED GRAMMAR 1
1 --> A,B,3,2,C,D,A,B,3,2,3,Q,R,P,2,C,D
2 --> Q,R,A,B
3 --> C,D,P
Encoding of raw data: 1
BADLY STRUCTURED GRAMMAR 2
1 --> Q,R,A,B
2 --> C,D,P
Encoding of raw data: A,B,2,1,C,D,A,B,2,1,2,Q,R,P,1,C,D
Figure 1
4.3 Grammars and Other Systems
There is a more than superficial analogy between these example grammars and other kinds of formal system. The analogy extends to cognitive and computing systems in general - hardware, software or both:- Every system has a size measurable in terms of the amount of information (bits) needed to
specify the system.
- Every system has more or less power, comparable with the expressive power of the example grammars. For example, a 'bare' computing machine, without software, is a relatively poor tool for doing any particular kind of task, eg processing accounting data and producing accounting reports. The addition of an operating system makes it more powerful in this sense and the further addition of an accounting package makes it even better. 'Power' in this context means much the same as 'usefulness' or 'functionality' and seems to be equivalent at some level of abstraction to the notion of expressive power introduced in last section.
In addition to the dimensions of simplicity and power seen in grammars and in computing systems, there is the concept of efficiency (the ratio of power to size) which we saw in connection with grammars and which seems also to apply to other systems. Efficiency in this discussion means 'doing a lot with relatively little'. It corresponds with the intuitive notion of 'elegance' or 'prettiness' of design.
A method of calculating simplicity (size), power and efficiency of grammars is described in the Appendix.
4.3.1 An Abstract Space for Grammars and Computing Systems
Figure 2 summarizes the ideas introduced so far. It is a set of graphs representing an abstract 'space' within which any grammar, formal system, knowledge structure or computing system may be placed. Each structure is a point in the space. The 'x' axis records the size of a structure; the 'y' axis records its descriptive power. These graphs represent imaginary data but are similar to unpublished graphs obtained from program SNPR - the program for grammatical inference which is described in Wolff (1982).Each of the curves in the figure represents the trade-off between size and power. Each of the higher curves represents a set of well-structured, efficient systems with good ratios of power to size. The lower curves are for poorly-structured, inefficient systems with low ratios of power to size.
Where a structure should be positioned up or down a curve depends on the relative importance of size and power and this will vary with the application. However, in all circumstances, the aim should be to maximize efficiency - the ratio of power to size. In grammatical inference, we need to find or create grammars which fall on or near the line marked '1' in the figure. In the design of computing systems we need to create systems which fall on or near that line.
No system can have more descriptive power than the raw data to which it relates. Hence the 'ceiling on power' in Figure 2.
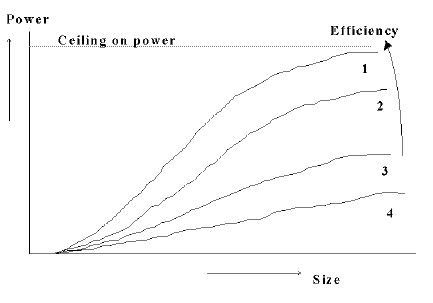
Figure 2
4.4 An Analogy
It may be helpful at this point to describe an everyday analogy for the relationships shown in Figure 2. The analogy is fairly accurate but not completely so.The relationship between size and power (in the senses intended here) is similar to the relationship between cost and value in the purchase of goods or services.
The trade-off between size (simplicity) and power is like the dimension from 'down market' to 'up market' which is so familiar when we are buying things. For a given type of commodity we may choose to go for lower cost and less value or we may choose to pay more for something which is higher quality or in some other way more valuable.
Of course, we all know that you do not always 'get what you pay for'. Independent of the up- market/down-market dimension is the notion of 'value for money'. Whether we are buying at the low or high ends of the market, a given sum of money can yield either poor value or good value. The notion of value for money is analogous to the notion of efficiency introduced earlier.
The cost and value analogy should not be stretched too far. Value, in particular, can be subjective and relative to a particular buyer. By contrast, the notions of size, power and efficiency can in principle be measured precisely in terms of information theory and without reference to subjective judgements.
4.5 Constraint and Freedom, Power and Simplicity, AND Relations and OR Relations
The trade-off between simplicity and expressive power in a grammar corresponds with a balance between freedom and constraint in the grammar. The second primitive grammar in Figure 1 provides the freedom to generate an infinite range of strings using the basic symbols. The first primitive grammar in Figure 1 is constrained to one string of symbols.'Freedom' in this context corresponds to OR relations and 'constraint' corresponds to AND relations in the grammar. The trade-off between compactness and expressiveness is mirrored by the balance between OR relations and AND relations in a grammar.
These ideas also map onto basic information theory: 'freedom' means choice which means low information content; 'constraint' means reduced choice and raised information content.
Figure 3 illustrates the way the dimensions of 'freedom-constraint', 'simplicity-complexity' and degrees of 'functionality' are related. At the top of the diagram is a 'raw' computing machine representing relative simplicity, a high degree of freedom but low functionality. Below this are layers of organization representing decreasing freedom but increasing complexity and increasing functionality.
4.6 Efficiency and Redundancy Extraction
The efficiency of our two well-structured grammars was achieved by the extraction of redundancy in the original data and a corresponding compression of those data. Extraction of redundancy appears to be the key to achieving a favourable ratio of simplicity to power.4.6.1 Avoid Repetition of Information
The basic idea in extracting redundancy from information is to avoid storing information more than once when once will do. Here are three ways in which this can be achieved:- Method 1. In the two well-structured grammars in Figure 1, the patterns A,B,C,D and
P,Q,R, which repeat themselves irregularly in the raw data, are stored once and accessed
via pointers or references from inside the grammar in the case of the first well-structured
grammar and from outside the grammar in the case of the second.
- Method 2. These two patterns:
A,B,C,D,P,E,F,G,H
A,B,C,D,Q,E,F,G,HMay be reduced to A,B,C,D,x,E,F,G,H, where x --> P | Q. Alternatively, the two patterns may be represented as A,B,C,D(P | Q)E,F,G,H.
- Method 3. Where a pattern or type of pattern repeats in a sequence of contiguous instances, this may be reduced to a single instance with some indication that it repeats. A sequence like A,A,A,A,A,A,A,A,A,A may be reduced to a recursive rule or it may be treated as 'iteration'.
The first of these examples illustrates the principle of structure sharing as a means of reducing or eliminating redundancy in data: a repeating pattern of information is stored once and accessed via references from the several contexts in which it occurs. A major motivation for using references in computing is to achieve the extraction of redundancy from data by means of structure sharing. A commonplace example is the use of named procedures and functions in computer programs, and calls to those procedures or functions from diverse contexts.
4.7 Pattern Matching and the Hill-Climbing Search for Efficient Structures
The three methods of extracting redundancy from information, described above, all depend on pattern matching and unification of patterns. Where a pattern of information repeats itself, the repetition can be avoided by creating one copy to replace all instances of the pattern: the replicated patterns are unified.In most realistically large bodies of data there is a very large number of alternative ways in which patterns may be matched and unified. In these circumstances, the set of unifications to choose is the one which maximizes C where:
i=n
C = SUM fisi
i=1
f is the frequency of pattern i in a body of raw data, s is its size (in bits or some equivalent measure) and n is the number of different kinds of pattern.
The patterns A,B,C,D and P,Q,R used in the two well-structured grammars in Figure 1 are better according to this measure than the patterns Q,R,A,B and C,D,P used in the two badly structured grammars.
There is no algorithmic way of ensuring that C is always maximized. Except for trivially simple cases, it is always necessary to use the kinds of search techniques familiar in artificial intelligence (most notably, hill climbing). These techniques cannot guarantee a perfect solution but they provide a practical means of finding at least an approximation to the desired goal.
An example of the application of hill-climbing to redundancy reduction by pattern matching and unification is described in detail in Wolff (1982). Winston (1984, Ch. 4) provides a useful introduction to the concept including the the idea of 'local peaks' and methods of avoiding them. In the context of computing with simulated neural networks, the technique of 'simulated annealing' has proved to be an effective means of reducing the chances of the system getting stuck on local peaks (see, for example, Hinton & Sejnowski, 1986).
4.8 De-referencing as Pattern Matching and Unification
As described above, when two or more patterns have been unified, references are often used to
mark the contexts in which the original patterns occurred. A pattern may be brought back into its
original context by de-referencing its identifier. But de-referencing is itself an example of
pattern matching and unification of patterns. To achieve de-referencing, a match must be found
for the reference elsewhere in the structure - and the two matching patterns must be unified.
A good example to illustrate this point is the way a named procedure in a computer program may be 'called' from several different contexts. The procedure name is associated with the body of the procedure in one part of the program. A reference to the procedure appears wherever the procedure is needed in other parts of the program. A 'call' to the procedure means searching for the name which matches the reference and unifying them.
Memory 'pointers' and memory 'addresses' may also be seen in these terms. Accessing an area of memory means searching for the address which matches a pointer and unifying them. The search process in this case is rather simple but it is search, nevertheless.
4.9 Modelling the World
As we have seen, there is a close connection between the concept of structure and the concept of
efficiency. Efficient grammars are well-structured grammars and they are also the grammars which
capture the redundancy (or structure) in the raw data.
When these ideas are generalized to other kinds of computing system, we find ourselves in familiar territory: a computing system is well structured to the extent that it reflects ('captures', 'models') the structure of its inputs and of its outputs. This principle has been propounded most persuasively by Michael Jackson (1975). It figures in the use of 'entity-relationship models' as a basis for the design of commercial software systems (LBMS, 1986). The principle is also an important part of the philosophy of object-oriented design (see, for example, Birtwistle et al., 1979; Cook, 1986).
The principle of modelling a computer system on the structure of the material it has to deal with is well recognized but the significance of this principle is, perhaps, not fully appreciated.
Normally it is justified on the grounds that it facilitates thinking about design and it makes it easier to modify designs. Both these justifications are sound but there is the additional, and related, reason that it is a means of maximizing the functionality of the system for a given cost in the complexity of the system (or minimizing complexity for a given functionality). Systems designed to conform to this principle are more efficient (in the sense defined above) than otherwise.
In general, systems which are 'efficient' are ones whose structure reflects or models the 'natural' structures in the external data. 'Natural structures' are patterns in the data which are 'coherent'. Patterns are 'coherent' when they repeat frequently in the data. Natural structures in this sense include such things as 'objects', 'entities', 'relationships' and, as we shall see later, 'classes' of these things.
4.10 Useful and Useless Redundancies
The idea that 'elegance' or 'prettiness' in design are closely bound up with the extraction of
redundancy in information is not in conflict with the well-known uses of redundancy in computing
systems to increase speed of processing or the reliability of systems or both.
For example, it is normal practice in computing to create 'backup' or security copies of information as a protection against losing the information altogether. A backup copy is redundant in the sense that it replicates the original data. Here, the redundancy between the original and its copy is useful.
By contrast, redundancy within each copy arising from poor structuring of the information is not useful and should be minimized. 'Management of redundancy' means, to a large extent, the removal of unnecessary redundancy or complication in a structure.
The use of references or identifiers to achieve structure sharing is an interesting example of useful redundancy. To achieve this effect, the identifier must appear in association with what it identifies and it must also appear in each of the contexts where the material is referenced. In this case a small amount of redundancy is introduced into a knowledge structure as a means of achieving a relatively large reduction in redundancy: structure sharing only makes sense if the material to be shared is bigger than the identifier used to achieve the sharing.
4.11 Summary
Here is a summary of the ideas introduced so far:
- Fundamental principles for the organization of formal systems and computing systems may
be seen in a relatively transparent form in the organization of simple grammars.
- Any grammar, other formal system, knowledge structure or computing system may be seen
as a means of succinctly describing information which is external to the system - inputs,
outputs or both.
- Any system has a place in a space defined by two dimensions: simplicity (or size or
complexity - meaning the information content of the system) and expressive or descriptive
power (meaning the effectiveness with which the system can represent or manipulate its
external information).
- There is a trade-off between simplicity and power.
- The balance between simplicity and power in a system corresponds to the balance between
OR relations and AND relations in the system.
- The efficiency of a system is the ratio of power to size.
- Efficiency is obtained by capturing or extracting the redundancy the redundancy in the external
information.
- Efficiency in this sense seems to correspond to the intuitive notions of 'good structure' in
a system, 'elegance' or 'prettiness' in design. A well-structured system reflects or models
the structure of its external data: objects or entities, relationships and classes.
- The basic principle of redundancy extraction is to avoid recording a pattern more than
once when once will do. Often this means the use of the principle of structure sharing and
this means the introduction of references between one structure and another.
- Redundancy extraction may be achieved more generally by pattern matching and the search (by hill climbing or equivalent process) for as much unification as possible. Notions of 'reference' and 'de-referencing' may be subsumed by these notions.
5. ORGANIZING PRINCIPLES
A main proposition from the last section is that any system may be placed anywhere in the space of possible systems by the application of two basic organizing principles:- AND relations.
- OR relations.
These principles appear to have a fundamental significance in the organization and use of formal systems, knowledge structures and computing systems of all kinds.
Some of the importance of AND relations and OR relations is recognized in Michael Jackson's principle (1975) that any sequential file of data may be described in terms of sequence, selection and iteration; and likewise for any program using that file as data (see also Bohm & Jacopini, 1966). In general, however, the fundamental significance of the principles which have been described in previous sections seem not to be widely recognized.
To get a feel for the generality of the organizing principles we can briefly survey some of the ways in which they currently appear in computing.
5.1 AND Relations
Here are some examples of AND relations in computing:
The types of identifier for an object (and thus the means by which it may be referenced) include:
29-Mar-98
The first three methods of identification may be seen as being 'content addressable' if the
information used to identify an object is seen as being a part of that object.
The extreme case of identifying an object by its constituents is where the whole object stands for
itself. This may seem an idiosyncratic, perhaps meaningless, view of the notion of identification
but, if we do not allow this notion, we are forced into arbitrary distinctions which lead to
unwelcome complications in our view of the subject.
As an illustration of the idea of an object standing for itself, each word in this text may be seen as
an AND group of references to its constituent letters. Each letter is an object which stands for (is
a reference to) itself. Creating special identifiers for each letter is less economical than using the
letters directly.
From the following examples we can see some of the range of applications of pattern matching in
existing systems and, to a lesser extent, search for good unifications:
SP owes its greatest debt to Prolog but differs from Prolog in interesting ways:
Although this will be less obvious, the language also owes a debt to object-oriented languages like
Simula, Smalltalk and LOOPS. As I shall show in section 7.3, it supports the notions of classes and
sub-classes, inheritance of attributes and part-whole relations. SP differs from all current OO
languages in being significantly simpler and, in a theoretical sense, more 'clean'.
The Lisp-like qualities of the language will be obvious.
Between any two simple objects which are immediately contiguous there must be at least one
space, comma or new line. Otherwise, as an aid to readability, zero or more spaces, commas or new
lines may be used in any desired combination between objects.
A 'symbol' may be a single character or a string of characters. In terms of the definition of SP, a
string is an Ordered-AND-object of characters. The reason for having 'symbol' as a distinct
construct (and not using the term 'string') is that symbols, unlike Ordered-AND-objects, will be
treated as atomic.
To be practical, the SP language would need such constructs as 'integer' and 'real'. The
assumption here is that such concepts and the operations which relate to them (addition,
multiplication etc) may be defined in SP and need not be supplied as primitives. Justification of
this claim is beyond the scope of this paper.
The meanings of the types of object should be reasonably clear from their names:
All computing is done by searching within the composite program-data object to find patterns
which match each other; when patterns do match they may be unified. The search space is usually
very large; where there is recursion, the search space is infinite.
Pattern matching may be 'free' or 'constrained':
There is no algorithmic way to ensure that the maximum possible amount of unification is
always achieved. Any practical version of 'broad' SP will have to use hill-climbing search
techniques of the kind described in Wolff (1982). These may reliably find more or less
'good' unifications but cannot guarantee that the best will always be found. To cope with
big search spaces in a practical way, Broad SP also demands high levels of parallel
processing in pattern matching and unification.
Like chess programs, versions of Broad SP may vary in how deeply the search tree is
explored before decisions are made. Alternatively, the depth of exploration in Broad SP
may be controlled by a parameter.
Broad versions of SP may be regarded as the canonical forms of SP. All other versions may
be regarded as approximations to the ideal.
SP may be constrained to work more like Prolog or a conventional programming language
(eg Pascal, C or functional languages like Lisp) by being more restrictive about how the
search for matching patterns is done. Here are three of the more obvious kinds of
restriction:
These and other kinds of restriction on pattern matching may be regarded as ways of
reducing the size of the space of possible unifications which the system has to search and
thus making the search tractable within the limits on processing power imposed by
currently available hardware. The penalty of these restrictions is that they limit the range
of problems which the computing system may solve.
It is normal for there to be many alternative possible unifications. A more realistic example
appears in section 7.1. The 'best' set of unifications is the one which reduces the size of the
structure by the greatest amount. As we have seen, there is no algorithmic method which is
guaranteed to find the best set of unifications in all cases. An SP 'engine' will depend on
hill climbing search techniques or something equivalent.
In general, the effect of unifying two OROs is to form the intersection of the two
sets of constituents.
The rules described in this section are not fully developed - more work is needed in this area. There
is a case, in future work, for introducing 'weights' on SP objects to reflect (absolute and contextual)
frequencies of objects in the raw data. The metric which evaluates alternative unifications will need
to accommodate these weights.
The introduction of weights is likely to lead to some modification in the rules just described,
particularly the rules for matching and unification with OROs. Two OROs may be unified by
taking the union of their constituents (rather than the intersection) but assigning higher weights to
items which are in the intersection.
In many ways SP has the organization of simple phrase structure grammars. In section 7.4 I will
show how SP overcomes the limitations of such grammars and has the power to handle
'context
sensitive' features in representations of knowledge.
Figure 5. A grammar written in SP
Figure 5 shows a little grammar written in SP. In this and later examples of grammars, the
distinction between upper and lower case letters has no formal significance; it merely helps one to
see which objects are serving as 'non-terminal symbols' and which represent 'text'. To forestall
misunderstanding, it should be stressed that SP is not a re-write system. The matching and
unification mechanisms in SP may imitate the effect of a re-write system but they are more general.
The example grammar may be used to parse a sentence by associating the sentence with the
grammar inside a UAO as shown in Figure 6.
Figure 6. Association of a sentence with a grammar
Figure 8 shows how the system may work in a 'bottom up' mode, where unification starts with the
sentence rather than the top rule of the grammar.
No further unification is possible without violating the order constraints on the sentence. This
solution is clearly much less economical than the 'correct' parsing and may be rejected on those
grounds.
SP has potential as a medium for expressing logical propositions and making logical inferences.
This is perhaps not surprising, given the significance in the language of the simple logical relations,
AND and inclusive OR.
Here is a familiar and elementary example:
In first-order predicate calculus this may be expressed as:
In SP, the same premises and the inference may be expressed like this:
Remember that '->' is not part of SP. It simply shows what is produced in the course of computing.
In the first line, the pattern [man,_] matches any UAO which has 'man' as a constituent object.
Thus it may be read as "all men" or "any man". The underscore symbol removes the need for a
universal quantifier rather in the way that Skolemization may be used to remove universal
quantifiers in predicate calculus. (Existential quantifiers are not needed either because any given
object may be named.)
The conjunction of 'mortal' with [man,_] gives the pattern [mortal[man,_]]. This represents "All
men are mortal". Likewise, [man,Socrates] represents "Socrates is a man". When these two
patterns are matched and unified, the result is [mortal[man,Socrates]] which may be read as
"Socrates is a man and he is mortal".
Thus SP does not derive [mortal,Socrates] directly from the two original propositions but creates
a pattern with which [mortal,Socrates] will unify. In this way, the proposition "Socrates is mortal"
is validated.
The problems mentioned earlier in finding matches between patterns and in differentiating
between 'good' and 'bad' matches, suggest that SP is too uncertain a medium on which to base
logical inference. But it is already known that every formal system which is expressive enough to
be useful is also 'incomplete' in the sense that there are truths which are expressible in the system
but which cannot be proved within the system. The uncertainty of matching and unification in
infinite search spaces may provide a reason for the existence of incompleteness in formal systems.
If every SP object is regarded as some kind of statement (it is, without doubt, a body of
information), then it may be regarded as true if it matches some other object, much in the way that
a Prolog Horn clause is regarded as true if a match can be found for it within a set of clauses.
SP differs from Prolog, of course, in that it allows partial matching. Correspondingly, it supports
the notion of degrees of truth. In general, truth in an SP system will be modelled by the metrics
which guide the search for 'good' structure within the system. There is no space here to discuss
fully the ramifications of these ideas.
In OO languages, classes serve as models for the creation of object 'instances'. This is similar to
the way in which types serve as models for the assignment of values to variables in other languages.
In most OO systems, classes are themselves objects which are instances of 'metaclasses'.
An idea which is complementary to the notion of class inclusion relations is the notion of part-
whole relations. This idea tends not to be explicitly recognized in OO systems but is there
nonetheless in the kinds of groupings and sub-groupings of objects which can be formed. Part-
whole relations form hierarchies and heterarchies as AND trees and AND networks.
Related to OO systems are the kinds of 'entity-relationship' (ER) models which are the stock-in-
trade of systems analysis (LBMS, 1986). Such models typically identify significant
'entities' in the
domain being modelled, 'attributes' of those entities and named 'relationships' between entities.
Although they do not usually figure in discussions of OO systems and ER models, three other
concepts will be mentioned here which relate to classes and categories. A class may be defined
extensionally by listing all the members of the class. It may also be defined intensionally by
describing the properties of the class. The third notion is that many of the classes we regularly use
in everyday life are polythetic. What this means is that there need be no single attribute which is
found in every example of the class. This property of natural categories has proved puzzling to
theorists who try to characterize classes in terms of defining characteristics. Polythetic classes
need not have any defining characteristics.
All the concepts described in the foregoing may be accommodated by the concept of an
'object' in
SP: 'class', 'super-class' and 'sub-class', 'metaclass', 'instance', 'function',
'method', 'message',
'class-hierarchy' and 'heterarchy', 'part-whole hierarchy' and 'heterarchy', 'entity',
'attribute',
'relationship', 'extensional definition', 'intensional definition' and 'polythetic class'.
The sets of three dots ('...') show where other information would go in a more fully developed
description. This structure shows the class 'person' as having the attributes 'head',
'body', 'legs',
'eats', 'sleeps' etc. These are the parts of which the concept of a person is composed; parts may
have sub-parts down to any level.
'Persons' have sub-classes 'tinker', 'tailor' etc and they are also cross-classified as
'male' or
'female'. Any number of levels is possible in this kind of classification scheme.
Notice how part-whole relations equate with AND relations, while class-inclusion relations equate
with OR relations.
An 'instance' of a person may be represented as:
If Mary is to eat something then one can send a 'message' to the object which represents her
something like this:
In SP, the concepts of 'instance', 'class' and 'meta-class' are merged. There is no attempt to create
'strict' hierarchies or avoid Russell's paradox. The advantage of this breaking down of the
distinction between classes and instances is the removal of unnecessary rigidities in the system:
any object may serve as a template for the creation of other objects (ie any object may serve as a
class) and any object may be created dynamically as the system runs. In other words, the structure
of classes of the system may evolve as the system runs.
Many people find it difficult to abandon the distinction between classes and instances. The reason
seems to be that the things which, in everyday life, are conventionally regarded as instances of
classes (eg individual people) are highly salient, coherent concepts. The fact that an individual
person (dog, cat, table, chair) is a very highly coherent concept should not disguise the fact that
such things are in fact collections of more primitive percepts. In short, they are classes of visual,
auditory and tactile images. Something which would conventionally be regarded as an instance, eg
'Mary', may be specialised into such concepts as 'Mary-as-wife-and-mother', 'Mary-as-
magistrate' etc. These are sub-classes of the class 'Mary'.
As a simple example, the SP object ({A,B}{C,D}{E,F}) represents the class of three letter strings
comprising ACE, ACF, ADE, ADF, BCE, BCF, BDE and BDF. No single attribute (letter) is found
in every example of the class. In general, polythesis is a reflection of disjunction (OR relations) in
the organization of knowledge.
Although SP resembles BNF, it can succinctly represent structures in natural language - such as
'discontinuous dependencies' in syntax - which are beyond the scope of BNF. SP has at least the
expressive power of 'context-sensitive' systems like Definite Clause Grammars (DCGs; Pereira &
Warren, 1980).
In the French sentence Les plumes sont vertes there are two overlapping sets of discontinuous
dependencies. They are shown here by underscores:
In the DCG formalism, which is a notational variant of Prolog, these dependencies would be
expressed throughout the grammar in a number of rules, including the highest level rule shown
here:
With SP, the same effect is achieved without any need for the meta rule. Figure 10 shows a small
grammar which can generate the example sentence amongst others. The 'top level' rule is simpler
than the top level rule in the DCG formalism because it does not attempt to record discontinuous
dependencies at this level. The grammar as a whole is significantly smaller than the equivalent
DCG grammar.
Figure 10. A fragment of French syntax written in SP
Computing in SP means searching for patterns which match each other and unifying them; where
alternative unifications are possible, which is almost always the case, then the SP system must
choose the 'best' one, meaning the one which allows the greatest amount of unification and a
correspondingly large simplification of structure.
This and the way SP treats partial matching means that a working SP system is likely to be
applicable to practical problems of pattern recognition. It is likely to have the kind of flexibility
long recognized in human pattern recognition: the ability to recognize whole patterns from partial
patterns and to recognize patterns despite distortion or fragmentation.
The subject of the second paragraph in this section was computing. But essentially the same thing
can be said about inductive learning. The inductive learning of a grammar, for example, can be
achieved by processes which at heart are pattern matching and unification, with the selection of
'good' (meaning economical) structures in preference to 'bad' ones (see Wolff, 1982, 1987, 1988).
Here is a very simple example to illustrate how an SP system may achieve inductive learning:
To infer grammars like those in Figures 5 and 10, the SP system would need to be able to create
new identifiers for structures (eg NP in (NP{john,mary}) and VP in (VP(V,_)(NP,_)) and
introduce them at appropriate points.
The potential applications of a system with inductive learning capabilities include: automation of
the process of building natural language grammars; automation of the process of
'knowledge
acquisition' for expert systems; optimization of database structures; inductive learning of
structures for pattern recognition; automatic programming.
The inductive properties of SP give the added dimension of adaptability to pattern recognition
applications. A pattern recognition system based on SP is likely to have the capability to learn new
general schemas from unprocessed input. It has long been recognized that much of the power of
human pattern recognition in, for example, speech recognition, lies in the dynamic adaptation of
the system to changes in the input. Pattern recognition and inductive learning are intimately
related.
Many of the ideas described in section 7.3 - on the representation of class-inclusion
relations, part-whole relations and 'relationships' between entities - may be applied to
problems of configuration management.
There is scope here for the integration of configuration classes with other classes in a
software system: the creation of a new version of a body of software would mean the
creation of new sub-class of the appropriate class in the system.
SP may alleviate these problems on all three fronts:
The rule may work backwards: from the existence of rain may be inferred the certainty of
there being clouds. In general SP supports the retrieval of complete patterns from partial
patterns. It will also support forwards and backwards chaining.
It should be clear from this example that SP can support the drawing of 'probabilistic'
inferences. It would be natural in making these inferences to utilize the 'weights'
mentioned earlier, reflecting the frequencies of objects in the raw data.
Uncertainty can be represented directly in SP using OROs. Gaps in knowledge may be
represented with variables ('_'). The design of SP accommodates uncertainty and
incomplete knowledge without ad hoc provision.
It is not possible to be very precise at this stage, but it seems likely that the inferential
processes embodied in the semantics of SP will lend themselves to the kind of 'automatic
planning' which figures in some commercially available systems to support project
planning and which has been the subject of extensive research (see, for example, Tate,
1985).
Amongst the potential benefits of an SP database are:
The simple and regular nature of SP, its close relation to logic (discussed above), and its
complete independence of any machine-oriented concepts, means that it should be regarded
as a specification language and not a 'programming' language in the conventional sense.
Like Prolog, it has potential as an 'executable' specification language. An SP specification
may run immediately without the need for the time consuming and error-prone processes
of 'refining' a specification to become an 'implementation' or 'program' followed by
'verification' that the 'program' conforms to the specification. Of course, it does not
eliminate the need to validate the specification against the user's requirements.
Much software design entails the recreation of routines for pattern matching and unification
in a variety of guises. By providing powerful and 'universal' methods of processing
patterns, SP can save much re-invention of the wheel.
In any kind of translation (including translation between natural languages) there are
advantages in using an 'interlingua' or base form as an intermediary between languages.
The main reason for this is that the number of translators which need to be developed may
be reduced: for all combinations of N languages the number of two-way translators
required is N! without an interlingua but only N with an interlingua.
If SP does indeed capture the essentials of computing in the way which has been claimed
then it should be a good choice as an interlingua for translation between existing computer
languages.
SP has potential to provide the general format which is needed for the uniform storage and
use of diverse kinds of knowledge.
It may not always be convenient to map every body of knowledge to the SP syntax. In these
cases, SP can serve a useful purpose as a framework within which 'alien' bodies of
knowledge may be stored. It can, for example, be used to show (in a UAO) the association
between a program written in, say, COBOL, and its corresponding compiler.
In this article I have tried to show with examples how a few carefully chosen basic constructs may
illuminate a wide range of concerns in computing. No attempt has been made to show how SP
would apply to such things as numerical computing, the representation and use of (2D and 3D)
geometric information, concepts associated with the interface between a computer and its human
user, or the representation and use in computational form of concepts of time.
There is a substantial programme of work needed to explore the adequacy or otherwise of SP
constructs in the kinds of areas mentioned. If SP and its underlying theory are sound then they
should have something useful to say about areas like these. It should be possible to create
'higher
level' constructs from the basic constructs in SP to meet the needs of particular domains.
It may be that the basic constructs in SP will need to be modified or augmented. However, in all
circumstances, we should resist the temptation to postulate new basic constructs in an ad hoc
manner. In accordance with the best scientific traditions, we should try to achieve descriptive and
explanatory power with a small range of theoretical devices. In short, we should aim in our thinking
for a favourable combination of simplicity and power.
Bohm C & Jacopini G (1966). Flow diagrams, Turing machines, and languages with only two
formation rules. Communications of the ACM 9(5), 366-371.
Cook S (1986). Languages and object-oriented programming. Software Engineering Journal 1(2),
73-80.
Hinton G E & Sejnowski T J (1986). Learning and relearning in Boltzmann machines. Chapter 7
in D E Rumelhart and J L McClelland (Eds), Vol I, pp 282-317.
Jackson M A (1975). Principles of Program Design. London: Academic Press.
Rumelhart D E & McClelland J L (Eds)(1986). Parallel Distributed Processing, Vols I and II,
Cambridge Mass.: MIT Press.
Structured Systems Analysis (1986). Learmonth & Burchett Management Services, London.
Peeling N E, Morison J D & Whiting E V (1984). ADAM: an abstract database machine. Report
No. 84007, Royal Signals and Radar Establishment, Malvern, UK.
Pereira F C N & Warren D H D (1980). Definite clause grammars for language analysis - a survey
of the formalism and a comparison with augmented transition networks. Artificial Intelligence 13,
231-278.
Tate A (1985). A review of knowledge-based planning techniques. In M Merry (Ed), Expert
Systems 85: Proceedings of the Fifth Technical Conference of the British Computer Society
Specialist Group on Expert Systems, Cambridge: Cambridge University Press, 89-112.
Ungar D & Smith R B (1987). Self: the Power of Simplicity. Proceedings of the Conference on
Object Oriented Programming Systems and Languages (OOPSLA '87), 227-241.
Winston P H (1984). Artificial Intelligence, Reading, Mass.: Addison-Wesley, Second Edition.
(1977: First Edition).
Wolff J G (1982). Language acquisition, data compression and generalization. Language &
Communication 2(1), 57-89.
Wolff J G (1987). Cognitive development as optimization. In L Bolc (Ed), Computational Models
of Learning, Heidelberg: Springer-Verlag, 161-205.
Wolff J G (1988). Learning syntax and meanings through optimization and distributional analysis.
In Y Levy, I M Schlessinger and M D S Braine (Eds), Categories and Processes in Language
Acquisition, New York: Lawrence Erlbaum, 179-215.
Figure 2. An abstract space for grammars and computing systems.
AND relations are often treated as being ordered; probable exceptions in the examples just given
are fields in a relational table, fields in records or structs and the relationship between a syntactic
structure and its semantics.
5.2 OR Relations
Examples of OR relations in computing:
5.3 Identifiers and References
The use of identifiers in conjunction with AND relations and OR relations results in the trees and
networks which are so widespread in computing: hierarchical directories of files, the structure of
function or procedure calls in a typical computer program, plex structures in a network database,
the structure of 'include' files in a typical C program or system, the structure of a non-overwriting filestore like ADAM (Peeling, Morison and Whiting, 1984).
5.4 Pattern Matching, Hill Climbing and Unification
Pattern matching is a recognized technique in computing (see, for example, Winston, 1977, Ch.
14) but the possibility that all kinds of computing may be seen as the extraction of redundancy by
pattern matching and hill climbing search for the best possible unification seems not to be generally
recognised: the section on pattern matching is omitted from the second edition of Winston's book
(1984) and the topic does not even get an entry in the index.
6.THE SP LANGUAGE
The syntax of the SP language, shown in Figure 4, is extremely simple. Since it represents a
distillation of existing ideas in computing, there should be no surprise that the language is similar
in certain respects to existing languages.
6.1 The Syntax
Figure 4. The syntax for SP
6.2 The Semantics of SP: How it is Intended to Work
This section describes the possible ways in which the language may be made to work - ie to do
some computing. A formal definition of the semantics has not yet been attempted.
The symbols '->' and '...' which appear later in the article are not part of the SP language.
'->' is
used to show when one SP object gives rise to another in the course of computing.
'...' is used in
SP examples to show where other information would go in a more fully developed description.
6.2.1 Computing
To create 'results' using SP, the 'data' and the 'program' must be associated. This is done by
joining them together within an AND object. Quote marks have been used for 'results',
'data' and
'program' because these distinctions are not recognized in the system and a uniform notation is
used for them all.
There is a variety of ways in which constraint may be applied in the SP system and varying degrees
of constraint - and there can be corresponding varieties of the SP language:
6.2.2 Rules for Matching and Unification
Here are the rules required for pattern matching and unification in SP:
7. APPLICATIONS
In this section I shall illustrate the workings of SP and the principles on which it is based using
examples from several areas of computing.
7.1 Parsing with a Simple Grammar
This first example, showing how SP may be used to represent a simple grammar and parse a simple
'sentence', may at first sight seem remote from the mainstream of computing. The justification for
first illustrating the workings of SP in this way is the belief that many aspects of computing may
be seen in these terms.
[
(S(NP,_)(VP,_))
(NP{john,mary})
(VP(V,_)(NP,_))
(V{loves,hates})
]
[(john,loves,mary)
Consider, first of all, a 'top down' parsing, where the processes of matching and unification are
driven by the 'top level' rule in the grammar: (S(NP,_)(VP,_)). Taking the components of this
object in turn, left to right, the system tries to unify as much as possible of this object with other
objects in the 'universe' of objects in the combined sentence and grammar. The same applies to
any new objects created by unification. The sequence of matchings and unifications is shown here:
[
(S(NP,_)(VP,_))
(NP{john,mary})
(VP(V,_)(NP,_))
(V{loves,hates})
]]
/* By unification of (NP,_) with (NP{john,mary}) */
/* By unification of {john,mary} with 'john' in (john,loves,mary) */
/* By unification of (VP,_) with (VP(V,_)(NP,_)) */
/* By unification of (V,_) with (V{loves,hates}) */
/* By unification of {loves,hates} with 'loves' in (loves,mary) */
/* By unification of (NP,_) with (NP{john,mary}) */
/* By unification of {john,mary} with 'mary' */
Figure 7. Unification in a 'top down' parsing of the sentence in Figure 3
using the grammar in Figure 3
Some comments on Figure 7:
/* By unification of 'john' in (john,loves,mary) with (NP{john,mary}) */
/* By unification of (NP,john) with (S(NP,_)(VP,_)). There is a conflict
here because (NP,john) may also be unified with (VP(V,_)(NP,_))
giving ((VP(V,_)(NP,john))(loves,mary)). In this example, this second
'bad', alternative will not be followed through. This kind of conflict is
discussed in the text. */
/* By unification of (V{loves,hates}) with 'loves' in (loves,mary) */
/* By unification of ((V,loves),mary) with (VP(V,_)(NP,_)) */
/* By unification of (VP,_) with (VP(V,loves){(NP,_),mary}) */
/* By unification of 'mary' with (NP{john,mary}) */
/* By unification of (NP,_) with (NP,mary) */
Figure 8. Unification in a 'bottom up' parsing of the sentence in Figure 6
using the grammar in Figure 6
In Figure 8 we see an example, at stage 3, of how rival unifications can arise. They represent
alternative solutions to the problem in hand. In principle, the system may be allowed to compute
all possible alternative solutions. For most purposes, it will be necessary to nip off any branch of
the search tree if it seems to be leading in an unhelpful direction. In terms of the theory on which
SP is based, 'unhelpful' means uneconomical. If the 'bad' path is followed at stage 3 of Figure 8
it will lead to this parsing:
((VP(V{loves,hates})(NP,john)),loves,(VP(V{loves,hates})(NP,mary)))
7.2 Logic and Logical Inference
All men are mortal.
Socrates is a man.
Therefore Socrates is mortal.
FORALL x is-member-of man . mortal(x)
AND Socrates is-member-of man
=> mortal(Socrates)
[[mortal[man,_]]
[man,Socrates]]
-> [mortal[man,Socrates]]
7.2.1 'True' and 'False'
SP has no explicit concepts of 'true' or 'false'. These concepts, which are primitives in other views
of computing may be seen as emergent properties of the SP system.
7.3 Object-Oriented Design and Entity-Relationship Models
This section discusses a set of inter-related ideas associated with object-oriented (OO) design and
with the creation of conceptual models.
The distinctive features of OO systems (eg Simula, Smalltalk and LOOPS) are:
In the more sophisticated OO systems (eg LOOPS), cross classification is possible with the
possibility of a class having multiple inheritance of attributes from two or more higher level
classes. A structure of interlocking hierarchies like this is sometimes called a
'heterarchy'.
7.3.1 Class-inclusion Relations, Part-whole Relations and Inheritance of Attributes
Figure 9 shows how class-inclusion relations, part-whole relations and inheritance of attributes
may be integrated.
[person [name,_]
((head ((eyes ...)(nose ...) ...))
(body ...)(legs ...))>
[eats ...][sleeps ...][breaths ...] ...
[profession
{[tinker ...]
[tailor ...]
...
}]
[gender
{[male ...]
[female ...]
}]]
Figure 9. The integration of class-inclusion relations, part-whole relations
and inheritance of attributes
[person [name,Tom],_,[profession[tinker,_]][gender[male,_]]]
or even more succinctly as:
[_,[_,Tom],_,[_,[tinker,_]][_,[male,_]]]
Either pattern will unify with the class schema giving a full description of 'Tom' something like
this:
[person [name,Tom]
(head ((eyes ...)(nose ...) ...))
(body ...)(legs ...)
(eats ...)(sleeps ...)(breaths ...) ...
[profession [tinker ...]]
[gender [male ...]]]
Pattern matching and unification provides a mechanism by which attributes may be inherited by
an instance (or sub-class) in the sense understood in object-oriented design. In SP, unlike most
other OO systems, the concepts of class-inclusion relation, and inheritance of attributes are
integrated with the concept of part-whole structure.
7.3.2 Methods and Messages
Narrow SP has potential as a 'procedural' language although the details will not be pursued here.
An SP object may contain constituent objects corresponding to 'methods' in other OO languages.
For example, a class 'person' containing the method 'eat' may be represented something like this:
[person, [name,_],[eat[food,_], ...], ...]
The first set of three dots corresponds to the details of how eating is done. The second set represents
the many other attributes of the class 'person'. A particular person may be represented as, for
example:
[person, [name,Mary],_]
or, more succinctly, [person,Mary,_].
[person,Mary,[eat,ham-sandwich],_]
Thus, in SP, both 'methods' and 'messages' may be treated as objects, not essentially different
from other kinds of knowledge. One advantage of treating 'methods' and 'messages' uniformly
with other kinds of knowledge is that 'inheritance' may be exploited within them. A
'method' may
be inherited by other objects and it may itself inherit objects from elsewhere. Likewise for
'messages'. Knowledge engineering systems like KEE go some way down this path.
7.3.3 Class, Meta-class, Instance and the Evolution of Classes
Most OO systems make a sharp distinction between 'classes' and 'instances'. Classes serve as
templates for the creation of instances but instances may not be templates for anything. The
structure of classes is established by a designer before the system runs and remains fixed while the
system runs. As it runs it may create new instances of classes dynamically but not new classes.
Since classes, in most systems, are regarded as objects, this means that they must be instances of
something. To avoid classes being instances of classes (which would violate the sharp distinction
between instances and classes) it is necessary to introduce the concept of 'meta-class'. Classes may
then be instances of metaclasses. There is an infinite regress because meta-classes must be
instances of meta-meta classes - and so on (see Ungar & Smith, 1987).
7.3.4 Entity-Relationship Models
Representing the relationship between two or more entities in SP is no different from representing
the structure of a given entity. The relationship may be expressed as an AND relation between the
relationship identifier and identifiers of the entities to be related. For example,
[employs,John,[Harry,Mary],_]
in the context of this schema:
[employs
[employer,_]
[employees,_]
...]
expresses the idea that 'John' employs 'Harry' and 'Mary'. The ellipsis represents other
information (eg company law) that may be associated with the relationship between employers and
employees.
7.3.5 Polythetic Classes
As already mentioned, most 'natural' categories are polythetic, meaning that there need not be any
single attribute which is found in all examples of the class. We can recognize something as, say, a
cat when any one (or perhaps more) of its distinctive features is missing or replaced by something
else. This property of natural categories is puzzling if one assumes that there must be defining
characteristics for classes, but it can be accommodated quite easily by SP.
7.4 'Context Sensitive' Power in SP
The expressive power of systems for constructing context-free grammars is limited. Systems of
this type (eg BNF) cannot, for example, adequately represent the syntax and semantics of most
natural languages.
Les plumes sont vertes
In the first case, the features of the sentence which make it plural are marked. All these parts must
agree even though they may be separated by any amount of intervening structure. Likewise, in the
second case, the parts of the sentence which express feminine gender must agree.
Les plumes sont vertes
s(Num,Gen,s(NP,VP)) --> np(Num,Gen,NP),vp(Num,Gen,VP).
In this rule, 'Num' and 'Gen' are variables recording number and gender, respectively. Agreement
is assured because of the 'meta' rule of Prolog that repeated examples of an instantiated variable
within a clause all refer to a single structure. If the first instance of 'Num' in the rule is instantiated
to 'singular' then all the others are too. Likewise for 'plural'. The 'Gen' variable behaves in the
same way for 'masculine' and 'feminine'.
[
Discontinuous dependencies for 'singular', 'plural', 'feminine' and 'masculine' forms are
expressed by the last four rules in the grammar, in that order. The '_' symbol, which will match
arbitrarily large amounts of structure, appears wherever there is structure which is irrelevant to the
dependencies being expressed. In this way the dependencies can be shown directly and plainly as
OAOs.
(S(NP,_)(VP,_))
(NP(D,_)(N,_))
(VP(V,_){(A,_)((P,_)(NP,_))})
(P{sur,sous, ...})
(V{(SING{est, ...})(PL{sont, ...})})
(D{(SING{(FEM{une,la, ...})(MASC{un,le, ...})})(PL{les, ...})})
(N(NS,_)(SUF1,_))
(NS{(FEM{plume, ...})(MASC{papier, ...})})
(SUF1{(SING,0)(PL,s)})
(A(AS,_)(SUF2,_)(SUF1,_))
(AS{noir,vert, ...})
(SUF2{(FEM,e)(MASC,0)})
(_,D,SING,_,N,_,SUF1,SING,_,V,SING,_{(A,_,SUF1,SING,_)_})
(_,D,PL,_,N,_,SUF1,PL,_,V,PL,_{(A,_,SUF1,PL,_)_})
(_,D,_,FEM,_,N,_,FEM,_{(A,_,SUF2,FEM,_)_})
(_,D,_,MASC,_,N,_,MASC,_{(A,_,SUF2,MASC,_)_})
]
7.5 Pattern Recognition and Inductive Learning
Perhaps the most interesting aspect of SP is its potential for pattern recognition, for inductive
learning and for their integration with other areas of computing.
[
would be reduced by the SP system to:
(John,runs)
(Mary,runs)
(John,walks)
(Mary,walks)
]
({John,Mary}{runs,walks})
This is functionally equivalent to a grammar which can 'generate' the four sentences from which
it was derived.
7.6 Other Applications and Attributes
There is no space in this article to discuss fully all the possible applications of SP. This section will
briefly describe some other areas where SP may be applied and properties of SP which may prove
useful.
[[cloud,{black,white}]{rain,hail,snow}]
If this rule is matched with [[cloud,black],_] representing the question "What do black
clouds mean?", the object [[cloud,black]{rain,hail,snow}] will be returned showing that
rain is a possibility.
8. CONCLUSION
SP and the theory on which it is based has potential to integrate and rationalize diverse concepts in
computing. The basic conjecture is that the organization and use of all kinds of formal system,
knowledge structure or computing system may usefully be seen in terms of the management of
redundancy in information.
9. ACKNOWLEDGEMENTS
Earlier drafts of this article have been circulated quite widely and several people have made useful
comments. I am particularly grateful to Simon Tait of Praxis Systems plc with whom I have
discussed these ideas extensively. I am also grateful for helpful comments from James Davenport
of the University of Bath; Tim Denvir, Anthony Hall, Trevor King, Paul Newman, Martyn Ould
and Lynn Robinson of Praxis Systems plc; Robert Kowalski of Imperial College, London; Peter
Van Peborg of Plessey Research; James Bond of the Central Electricity Generating Board, Bristol;
and Simon Jones of the School of Electronic Engineering Science, University of Wales (Bangor).
10. REFERENCES
Birtwistle G M, Dahl O-J, Myhrhaug B & Nygaard K (1979). Simula Begin, New York: Van
Nostrand Reinhold.
11. APPENDIX: THE CALCULATION OF SIZE, POWER AND EFFICIENCY OF GRAMMARS
The size (sr ), in bits, of a body of raw data may be calculated as
sr=nrcr
where:
The size (se ), in bits, of a body of data after encoding by a grammar may be calculated as
cr=log2tr
rounded up, where tr is the number of symbol types used in the raw data.
se=nece
where:
The size (sg ), in bits, of a grammar may be calculated as
sg=ngcg
where:
The descriptive power (pg ) of a grammar may be defined, with reference to a given body of raw
data, as
pg = sr - se
The efficiency (eg ) of a grammar, with reference to a given body of raw data is:
eg = pg / sg
12. FIGURE CAPTIONS
Figure 1. Data and grammars to illustrate concepts of simplicity and power.